
System design is an essential aspect of building software applications that are scalable, reliable, and maintainable. It involves the process of designing the architecture and components of a software system to meet specific performance and functionality requirements. In this blog post, we'll cover the basics of system design, including key concepts and principles, different system architecture patterns, and factors to consider when designing scalable and reliable systems.
 |
| Photo by Onur Binay on Unsplash |
Scaling
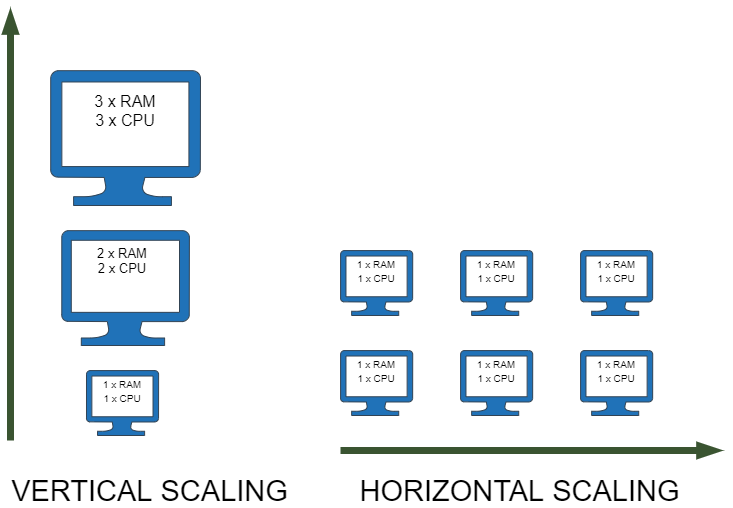
1. Vertical scaling
When building a software application, it's important to consider its scalability to ensure it can handle increasing loads of work over time. As the number of requests to the server increases, the load on the server can increase exponentially or linearly, resulting in downtime or slow response times.
One solution to this problem is to add extra CPU's or increase the RAM in the server to serve requests faster. However, this approach has its limitations. Adding more resources to a single server can become expensive, and it may not be possible to add more resources indefinitely as the demand for the application grows.
2. Horizontal scaling
In a scenario where a server goes down, the entire application can become unavailable, causing frustration for users and potentially leading to lost revenue. This is why it's crucial to eliminate single points of failure in the application architecture.
One way to achieve this is by distributing servers across multiple locations and creating replicas of the application. By replicating the application in multiple locations, if one server goes down, requests can be fulfilled by other servers, preventing downtime and ensuring the application remains available to users.
 |
Image src :- thehonestcoder |
Load Balancer
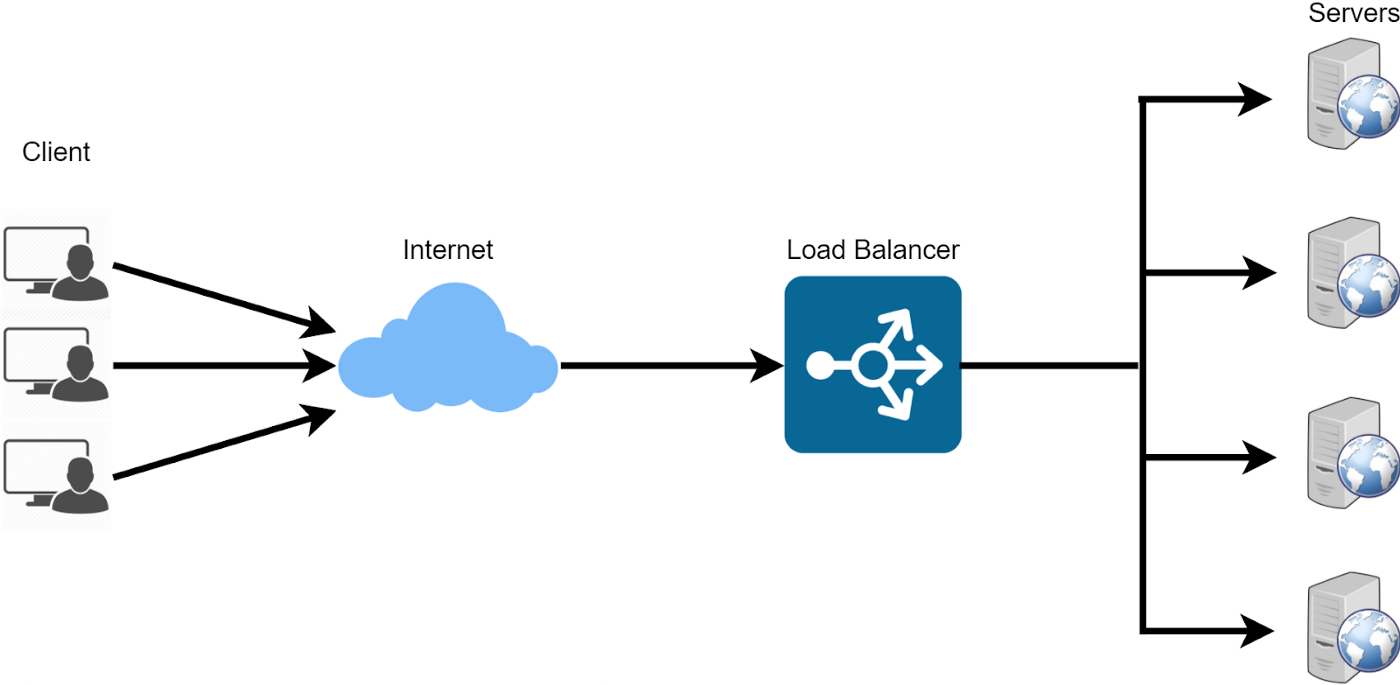
When it comes to scaling an application, horizontal scaling is generally considered to be a better approach than vertical scaling. However, even with horizontal scaling, there can be instances where one server is overloaded with requests, leading to performance issues and potential downtime.
This is where a load balancer plays a vital role in ensuring that requests are evenly spread across all servers. A load balancer acts as a traffic cop, routing incoming requests to multiple servers based on a variety of algorithms, such as round-robin, least connections, or IP hash.
By using a load balancer, the load on each server is balanced, preventing any one server from becoming overwhelmed with requests. This helps to ensure that the application remains performant and available to users.
The round-robin algorithm is a commonly used algorithm in load balancing. In this algorithm, the load balancer evenly distributes incoming requests across all available servers, ensuring that no single server receives more requests than the others. This helps to prevent server overload and ensures that all servers are being utilized efficiently.
 |
Image src AnalyticsVidhya |
CDN (content delivery network)
CDNs are used to serve static files such as images, videos, and HTML/CSS/JS files that make up a website.
When a user accesses a website that uses a CDN, the CDN serves the content from a server that is geographically closer to the user, reducing the latency and improving the overall user experience. This is achieved by storing the content on multiple servers in different locations around the world, known as edge servers.
When a user requests content from a website, the request is routed to the nearest edge server, which serves the content from its cache. This means that the content is delivered faster and more efficiently, improving the overall performance of the website.
Caching
When a user requests data from an application, the application first checks if the data is available in the cache memory. If the data is present in the cache, it can be retrieved quickly, without the need to access the slower main memory or retrieve the data from a remote server. This helps to reduce the load time of the application, improving the user experience.
Networking
Tcp/Ip model
The TCP/IP model is a protocol stack used for communication over the Internet and other networks. It is an improved version of the OSI model and consists of four layers:
- Application layer: This layer is responsible for end-to-end communication and defines the protocols used by applications to exchange data. Examples of protocols used at this layer include HTTP, HTTPS, SMTP, FTP, and Telnet.
- Transport layer: This layer is responsible for breaking data into smaller chunks, called segments, and transmitting them character by character between applications. The Transport Control Protocol (TCP) and the User Datagram Protocol (UDP) are two popular protocols used at this layer. TCP provides reliable, connection-oriented data transmission, while UDP provides fast, connectionless data transmission.
- Internet layer: This layer is responsible for routing data between networks and assigning IP addresses to devices. It uses the Internet Protocol (IP) to provide a logical addressing scheme for data transmission. IP assigns unique IP addresses to each device on a network and uses routers to forward data packets between networks.
- Data link layer: This layer is responsible for framing data into frames and performing error prevention. It includes two sublayers, the Logical Link Control (LLC) sublayer and the Media Access Control (MAC) sublayer. The LLC sublayer provides flow control and error checking, while the MAC sublayer provides access to the physical network medium.
- Physical layer: This layer is responsible for generating data and requesting a connection. It defines the electrical, mechanical, and procedural specifications for devices to connect to a network and transmit data.
DNS
What is the Domain Name System (DNS), and why do we need it? We know that data exchange always happens between IP addresses. Each website has its unique IP address, but remembering the IP of each website can be a challenging task. That's where domain names come in, mapping an IP to a domain name (e.g., 256.123.980 -> example.com). When we type in a domain name in the browser, it contacts the DNS provider to get the IP and then requests files stored on the respective IP server. However, isn't this process redundant? The browser must make requests to the domain name provider and ask about the IP every time. That's where caching comes in. The browser caches the IP so that it does not have to perform this task again.
Http
An application-level protocol helps us to request files or data from a server that follows the client-server model. When sending a request, it includes a request header that contains all the necessary information, such as whom to request and the IP address making the request. Additionally, it has a request body that holds the actual data that is being requested or received.

REST API
An API service enables the exchange of data between two machines. It has a variety of methods available, including:
- GET: used to retrieve or fetch data from the web service.
- POST: used to send data to the web service.
GraphQL
APIs (Application Programming Interfaces) are essential for communication between software systems. In 2015, Facebook introduced a new API service called GraphQL, which is designed to improve the efficiency and flexibility of API communication.
With GraphQL, clients can request all the data they need with a single query, instead of making multiple API calls to pull or push data. The client specifies the exact data it needs in the request, and the server responds with only that data. This reduces the amount of network traffic and simplifies the communication between the client and the server.
Web Sockets
- Websockets are a type of protocol that are useful for handling real-time data. Real-time data refers to any continuous stream of data, such as the data we get from a chat application.
- In a chat application, users may send messages to each other every second. Making an API request every second to retrieve this data from the server can be quite costly in terms of resources.
- Websockets solve this problem by allowing data to be sent and retrieved within a single request. This eliminates the need to send multiple requests for each update or message, making the process more efficient and less resource-intensive.
Database
SQL
Structured Query Language (SQL) is a domain-specific language used to manage relational databases and perform various operations such as storing, retrieving, and manipulating data. MySQL is a popular open-source relational database management system that uses SQL as its query language to interact with the database. Using SQL, users can create tables, add data to them, modify and delete existing data, and perform complex queries to extract specific information from the database. SQL provides a standardized syntax that can be used across various relational database systems, making it a valuable skill for developers and data analysts.
ACID
- Atomicity: Ensures that a transaction is treated as a single, indivisible unit of work, which either occurs completely or not at all. If any part of a transaction fails, the entire transaction fails and the database is rolled back to its previous state.
- Consistency: Requires that the database be in a valid state before and after each transaction. All data modifications must be consistent with the database's rules and constraints.
- Isolation: Ensures that each transaction is executed in isolation from other transactions. Transactions should not interfere with each other, and intermediate transaction states should be invisible to other transactions until they are committed.
- Durability: Ensures that once a transaction has been committed, it will remain permanently in the system, even in the event of power loss, crashes, or errors.
NoSQL
A non-relational database is also known as a NoSQL (Not only SQL) database. Unlike traditional relational databases, NoSQL databases do not store data in fixed tables with a structured schema. Instead, they store data in a variety of ways, such as graph nodes or documents. Examples of NoSQL databases include Firebase Firestore and MongoDB. NoSQL databases are often used for handling large amounts of unstructured or semi-structured data, such as social media posts or product reviews, and for applications that require horizontal scaling.
Cap theorem
- Consistency - all nodes see the same data at the same time.
- Availability - every request gets a response.
- Partition Tolerance - the system continues to function even when network partitions occur.
Lastly understanding these fundamental concepts in computer science such as caching, API services, databases, and CAP theorem can greatly enhance your knowledge and skills as a developer, and enable you to build more robust, scalable and reliable applications

{kind=link}
{kind=link}
{kind=link}
0 Comments